In the mathematical literature, numerous bounds can be found for the spectral norm of a matrix. Can we improve these bounds if the matrices are known to be Hermitian or even real symmetric semidefinite?
Let 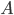 be an
be an 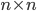 matrix. An induced matrix norm is defined as
matrix. An induced matrix norm is defined as
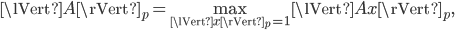
where 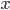 is a vector. The induced matrix norms
is a vector. The induced matrix norms 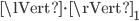 ,
, 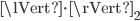 , and
, and 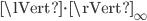 are called row sum norm, spectral norm, and column sum norm, respectively. On a computer, the row sum norm and the column sum norm can be calculated efficiently for dense and sparse matrices whereas the spectral norm requires the computation of the largest singular value - this is expensive in general. For example, for dense matrices, computing singular values requires
are called row sum norm, spectral norm, and column sum norm, respectively. On a computer, the row sum norm and the column sum norm can be calculated efficiently for dense and sparse matrices whereas the spectral norm requires the computation of the largest singular value - this is expensive in general. For example, for dense matrices, computing singular values requires 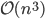 flops while the row sum norm and the column sum norm can be evaluated in
flops while the row sum norm and the column sum norm can be evaluated in 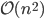 flops, i. e., in linear time in the number of matrix entries. Consequently, it may be necessary on a computer to replace spectral norms in algorithms with row sum norms, column sum norms, or a combination thereof but in this case, one would like to have tight bounds on the relative differences between the norms. In this post, we try to find tight bounds on the spectral norm given the row sum norm when a matrix is known to be Hermitian or real symmetric semidefinite. Note that for Hermitian matrices, the row sum norm and the column sum norm are identical. To preserve uniformity, I will only use the row sum norm in this blog post.
flops, i. e., in linear time in the number of matrix entries. Consequently, it may be necessary on a computer to replace spectral norms in algorithms with row sum norms, column sum norms, or a combination thereof but in this case, one would like to have tight bounds on the relative differences between the norms. In this post, we try to find tight bounds on the spectral norm given the row sum norm when a matrix is known to be Hermitian or real symmetric semidefinite. Note that for Hermitian matrices, the row sum norm and the column sum norm are identical. To preserve uniformity, I will only use the row sum norm in this blog post.
Improving the Upper Bounds
For the induced matrix norms of square matrices, we have (among others) the following norm equivalence:
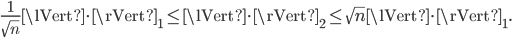
For Hermitian matrices, the upper bounds on the spectral norm are easily improved using the inequality
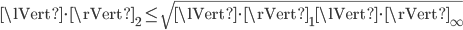
because for these matrices it holds that 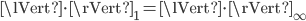 . Thus
. Thus
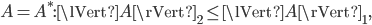
where 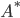 is the complex conjugate transpose of .
is the complex conjugate transpose of .
Improving the Lower Bounds
As a student assistant, I work a lot with the Harwell-Boeing BCS structural engineering matrices and for these matrices, the row sum norm is usually a good estimate of the spectral norm; therefore I was convinced that the lower bounds on the spectral norm should improve for Hermitian matrices. Since I was unable to come up immediately with an analysis, I decided to have the computer generate matrices to test my conjecture. For this purpose, I used direct search optimization: given an initial vector 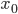 and a real-valued objective function
and a real-valued objective function 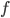 , the goal is to maximize . Nicholas J. Higham devoted multiple sections of his book Accuracy and Stability of Numerical Algorithms to direct search methods and he provides Matlab implementations of three algorithms of this kind as part of his Matrix Computation Toolbox. I used the multidirectional search method from Higham's toolbox. In this blog post, the optimization goal is to maximize
, the goal is to maximize . Nicholas J. Higham devoted multiple sections of his book Accuracy and Stability of Numerical Algorithms to direct search methods and he provides Matlab implementations of three algorithms of this kind as part of his Matrix Computation Toolbox. I used the multidirectional search method from Higham's toolbox. In this blog post, the optimization goal is to maximize
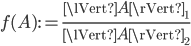
for symmetric matrices  and given
and given 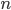 . Accordingly, the search space has dimension
. Accordingly, the search space has dimension 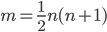 because we only need to generate the lower or the upper triangular part of the matrix . In order to strengthen my conjecture that the lower bounds
because we only need to generate the lower or the upper triangular part of the matrix . In order to strengthen my conjecture that the lower bounds 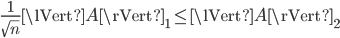 are not the best bounds for
are not the best bounds for 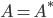 , the optimizer needs to fail to find with
, the optimizer needs to fail to find with 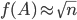 . To disprove the conjecture, it needs to find only one counterexample.
. To disprove the conjecture, it needs to find only one counterexample.
The optimizer quickly dealt a deadly blow to my conjecture: for 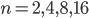 , the maximum value of
, the maximum value of 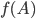 found by the optimizer was close or equal to
found by the optimizer was close or equal to 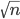 . Here is a
. Here is a  matrix that achieves the worst-case norm ratio
matrix that achieves the worst-case norm ratio 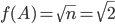 :
:
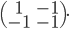
Here a  example by the optimizer:
example by the optimizer:
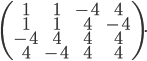
Note that you can replace the number four in the matrix with another value with modulus larger or equal to one. With a bit of thought, this example can probably be used to construct larger matrices with 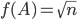 . Evidently, the existing lower bounds
. Evidently, the existing lower bounds 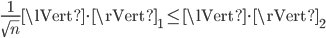 are tight for Hermitian .
are tight for Hermitian .
Improving the Lower Bounds for Semidefinite Matrices
All generated worst-case matrices had two things in common:
- they were indefinite,
- the moduli of the smallest and largest eigenvalue were equal or almost equal.
The Harwell-Boeing BCS structural engineering matrices I work with are all positive semidefinite so I decided to adjust my conjecture: for real symmetric semidefinite matrices, 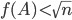 . Again, I employed direct search optimization to test the hypothesis. To that end, I had the search algorithm generate lower triangular matrices
. Again, I employed direct search optimization to test the hypothesis. To that end, I had the search algorithm generate lower triangular matrices 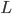 and set
and set 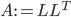 , that is, the optimizer was implicitly computing the Cholesky decomposition of some symmetric positive semidefinite (SPSD) matrix .
, that is, the optimizer was implicitly computing the Cholesky decomposition of some symmetric positive semidefinite (SPSD) matrix .
Let 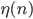 denote the maximum value of the computed for a given , , and SPSD. I did not save the initial set of results but what I saw was similar to the following values:
denote the maximum value of the computed for a given , , and SPSD. I did not save the initial set of results but what I saw was similar to the following values:
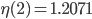 ,
,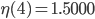 ,
,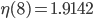 ,
,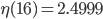 ,
,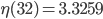 .
.
Clearly, these maxima are smaller than and we found some support for the claim that when is real symmetric semidefinite.
Now it would be interesting to know which function 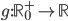 generates these
generates these 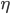 values so that we can compute lower bounds for the spectral norm. Clearly,
values so that we can compute lower bounds for the spectral norm. Clearly, 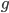 is not linear and I did not recognize a familiar number sequence here. Furthermore, if were a power function then
is not linear and I did not recognize a familiar number sequence here. Furthermore, if were a power function then 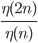 would be constant but this is not the case; if were an exponential function, then
would be constant but this is not the case; if were an exponential function, then 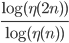 would be constant but this is also not the case. There are databases of number sequences on the internet and my next idea was to search for some of the computed values. Here is the fourth Google hit for the search term "1.207107 root".
would be constant but this is also not the case. There are databases of number sequences on the internet and my next idea was to search for some of the computed values. Here is the fourth Google hit for the search term "1.207107 root".

We found the answer:
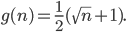
Conclusion
For Hermitian matrices, the existing bounds on the spectral norm are optimal but for real symmetric semidefinite matrices, I conjecture the following bounds hold:
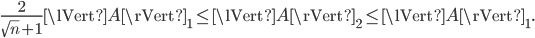
Edit April 15, 2016
The Matlab code for this article is available on gitlab.com.