Many new products nowadays were made possible by advances in machine learning, in particular image recognition and automatic speech recognition. Examples are spam filters, virtual personal assistants, traffic prediction in GPS devices, or face recognition. Real-world machine learning applications see more widespread use and enjoy ever increasing accuracy on common benchmark datasets. Unfortunately, it has been observed that virtually all models return incorrect results if data is fed to the model that is not from common benchmark datasets, data that was purposefully but imperceptibly altered, and plain garbage data. In this blog post I will talk about the purposeful, imperceptible input modifications, so-called adversarial examples. I will present possible kinds of modifications in computer vision and requirements for successful attacks before discussing attempts to improve models. Finally, I will make two predictions about the future of machine learning models. The appendix contains remarks about the misinterpretation of the largest eigenvalue of a weight matrix; the modulus of this value is almost meaningless without considering the smallest eigenvalues, too.
Introduction
The goal in machine learning is having a computer perform specialized tasks by fitting a statistical model to a set of previously observed pairs of inputs and outcomes. For example, a popular task is digit recognition where 32x32 grayscale images of handwritten digits have to be mapped to the digits zero to nine. Key challenges in machine learning are acquisition of many representative samples, selection of an appropriate statistical model, and fitting the statistical model to the given samples; model fitting is usually a hard optimization problem. Ideally, the fitted model would prove equally accurate for samples it was not trained on.
Around 2013, researchers first observed that the most accurate image recognition models of the time were susceptible to minuscule perturbations in the input. Specifically, given an image and a model, the researchers devised a method to compute perturbations leading to misclassification with high confidence [1, 2]. Since these perturbations were (almost) imperceptible by humans, these perturbed images were dubbed adversarial examples. The reference [3] contains examples for semantic segmentation, pose estimation, and automatic speech recognition. Nicholas Carlini's website has audio adversarial examples that one can listen to.
More research quickly improved existing approaches to compute perturbations (e.g., [4]) and to find uncountable new ways to fool image classifiers. The adversarial modifications can be
- small in norm over the whole image [5, 6],
- individual pixels (one to five pixels suffice) [7],
- synthesized from scratch [8],
- output from harmonic functions [9] (like from shade for example),
- rotations and translations of the original image [10],
- small colorful patches (so-called adversarial patches, [11]),
- an elephant [12], and
- changes to hue and saturation (semantic adversarial examples, [13]).
The adversarial examples above exploit that image classifiers may compute completely different classifications for similar images. The same classifiers were also shown to compute the same classifications for completely distinct images [14]. It is also possible to find a single perturbation small in norm causing all images to be misclassified, so-called universal adversarial perturbations [15, 16]; such a perturbation can also be used to improve classification accuracy [17]. Finally, adversarial examples can be used to re-purpose existing models for classification tasks they were not trained on [18].
Adversarial examples transfer well [19] meaning an adversarial example for a given model will in all likelihood also cause misclassification on
- the same model architecture with different weights as well as
- completely different model architectures, e.g., classification trees or support vector machines [20, 21].
Originally, the algorithms computing adversarial examples needed access to the model. In particular, these algorithms needed to be able to calculate the gradients for given inputs. This restriction was soon lifted and recent methods to compute adversarial need only observe probabilities for attacker-provided input [22, 23] or the classification of attacker-provided input [24]. Adversarial examples can also be computed if the objective function is non-differentiable [3]. As stated above, adversarial examples transfer well. For this reason it is also possible to craft adversarial examples on a substitution model.
Model inputs that are not from one of the classes the model was trained on are called out of distribution, the opposite being in-distribution data. Ideally a model should assign (approximately) equal, low confidence to all possible labels in response to out-of-distribution input. Fooling inputs [25] are examples for out-of-distribution input receiving high confidence labels.
The Implications of Adversarial Examples
Early into the research on adversarial examples, the question arose if adversarial examples carry over to the real-world. Initially, some researchers observed that if they printed adversarial examples on paper, photographed them, and fed to them to an image recognizer, then the classifier would still compute incorrect classifications most of the time [26]. Next, 3D adversarial print-outs followed [27] and adversarial attacks were attempted on models recognizing street signs [28] and camera lenses were tampered with [29]. Another group of researchers succeeded in adversarially modifying 3D meshes used for rendering; the rendered objects would then be reliably misclassified [30]. In March 2019, researchers succeeded in having a Tesla drive itself into oncoming traffic by fooling the lane assistant with an adversarial attack [31].
Adversarial examples are not specific to computer vision. For example, these attacks can also be performed on natural language processing models [32], malware detection models [33], automatic speech recognition model with sound recorded by a microphone [34, 35, 36], and medical models [37]. Examples for non-speech input that is interpreted as speech can be found on Nicholas Carlini's website.
In summary, machine learning reached a state where models are widely deployed in safety-related capacities. At the same, an attacker can easily craft malicious model inputs with or without access to the victim model. These malicious inputs go undetected by humans, they can rarely be detected by algorithms, and they can be passed directly (say, as image) or indirectly (played over air, after photographing) to the victim model. This is a recipe for disaster (imagine terrorists dropping confetti with adversarial patches on a highway in the rush hour).
In Search of Robust Models
As soon as adversarial examples had appeared, attempts were made to defend against them. Most defenses were quickly shown to be ineffective including actual defenses [38, 39, 40, 23] and methods to detect adversarial examples [41, 42]. Seven out of eight defenses submitted to a dedicated competition at the International Conference on Learning Representations 2018 (ICLR 2018) were broken before the actual conference took place [43].
There is growing evidence that adversarial examples are unavoidable in high-dimensional spaces because of the peculiarities of geometry [44, 45, 46]. For example, the effects of "high" dimensionality can be measurable with a number of dimensions as low as ten, under certain conditions the distances between the nearest and the farthest neighbor of a given point may then converge towards one, and the unit hypersphere is completely contained by the unit hypercube only for dimensions one to four, cf. [47, 48, 49]. In this scenario, feature engineering and dedicated feature detectors (e.g., for eyes in case of face recognition) would help. Some authors also pointed out the connection between noise robustness and robustness to adversarial examples [50], the connection being the geometry of the decision boundary between classes [51, 52, 53]. For the analysis of this link between noise and adversarial robustness, the intrinsic dimensionality of the input is again relevant.
Additionally, it was shown that training a model robust to adversarial examples requires much more training samples than a model with the same accuracy without this robustness [54]. Furthermore, it is possible that models robust to adversarial examples must exhibit lower accuracy than a non-robust model [55]. It is certain that models with 100% accuracy on the test set must be susceptible to adversarial examples [45].
Early on, it had been discovered that adding adversarial examples to the training set may convey some degree robustness; this is called adversarial training. The currently most effective adversarial training method is based on the reformulation of the optimization problem during model fitting [56]. The standard formulation is
Modify the model parameters so as to minimize the classification error for all training samples.
Usually though, one wants that similar model input is classified similarly resulting in a problem statement from the field of research called robust optimization:
Modify the model parameters so as to minimize the classification error for all training samples and map all points near a given training sample x to the same class as x.
This approach turned out the be the only working defense submitted to ICLR 2018. It increased the perturbation size by about factor four for a successful attack computing provably minimal perturbations [57]. This robust optimization procedure will defend only against the subset of adversarial examples created by perturbations small in norm; it will not protect against, e.g., adversarial image rotation and translation because the perturbed input is in the mathematical sense not "near" the original sample. The defense also fails as soon as the perturbation norm is slightly larger than the maximum perturbation norm used during model training and it does not work against attacks that minimize the Hamming distance (i.e., single pixel attacks).
Machine learning practitioners usually apply a different basic rules for neural networks than for other machine learning model architectures, e.g., models are routinely overparameterized and individual weights are not driven to zero unless model size is critical (the state-of-the-art ImageNet model AmoebaNet has 557 million parameters and there are approximately 1.3 million training samples). In response, some researchers contend that current machine learning models are routinely overparameterized [58] with adversarial examples being one consequence. To test this claim, a research group trained smaller models with stronger weight and they found their models [59, 60]
- were as robust to adversarial examples as models using adversarial training,
- possessed intuitively interpretable gradients, and
- assigned labels with less confidence to out-of-distribution inputs.
Conversely, adding out-of-distribution data to training has a marked regularizing effect [61].
Initially, it seemed that a combination of adversarial training, stronger weight decay, smaller models, and reduced accuracy of weights as well as activations might lead to robust models. Unfortunately, a group of researchers soon pointed out that the models using one of the techniques above had become susceptible to invariance-based adversarial attacks. That is, the labels do not change when they actually should [14].
Perturbation-based adversarial attacks prove that machine learning models may change labels in response to input modifications when they should not and invariance-based adversarial attacks demonstrate that labels do not change in response to input modifications when they should. Thus, models are not properly classifying in-distribution input. The high-confidence labels for fooling inputs are evidence that models cannot tell in-distribution and out-of-distribution data apart. In short, the models are clearly not working if you look closely.
Achieving adversarial robustness exerts a whole new set of demands on practitioners then. Adversarial training requires one backward propagation for every gradient computation, there is at least one backward propagation for every perturbation, and there is one perturbation for every adversarial example added to the training. Thus, training becomes much more expensive in terms of computing time. Strong weight decay confers adversarial robustness but does not work with some models, e.g., Wide ResNets [59], and decreases clean test set accuracy. Smaller models are more robust and speed up training but this is contrarian to the model growth in computer vision. Additionally, more robustness against perturbation-based attacks makes models more vulnerable to invariance-based attacks.
The Future
Conjecture: In general, adversarial examples cannot be detected.
Some authors try to detect adversarial examples [41, 42] and in my opinion this approach is doomed to fail except for specific types of adversarial examples (say, single-pixel perturbations) because the existence of adversarial examples is a symptom of a problem inherent to state-of-the-art machine learning models. Consider for example that every misclassified sample in a given training set can be thought of as an adversarial example: the input is indistinguishable from a benign sample of this class but still misclassified. Also, adversarial examples may improve accuracy [17] meaning detection would decrease accuracy. Finally, adversarial examples can be synthesized from scratch [8]. In [62] the authors attempt to detect adversarial examples by exploiting the observation that noise usually does not change the label of genuine input whereas noise added to adversarial examples easily does [63]. I think this observation only holds for attacks minimizing the perturbation norm (e.g., projected gradient descent [56] or the Carlini-Wagner attack [42]). Consequently, the expectation-over-transformation attack [27] should be able to craft adversarial inputs avoiding detection.
Prediction: In ten years, at most five percent of all deployed machine learning models will be robust to what were state-of-the-art adversarial attacks at the time of model training.
The major reasons for this are:
- Adversarial robustness is hard to pitch to stakeholders.
- The economics of adversarially robust models put them at a disadvantage.
- It requires a paradigm change.
Model accuracy is a single number that can be pitched to anyone, be it a friend, a team leader, a manager, a CEO, an investor, or a customer -- the higher, the better. Training an adversarially robust model for a given task immediately leads to a drop in accuracy in comparison to a non-robust model and makes it necessary to balance a whole set of contradictory requirements, e.g., robustness against perturbation-based as well as invariance-based attacks. Finally, since models are usually resilient to (small) random perturbations, one actually needs to convince the stakeholders that an adversary should be considered.
To add to that, training adversarially robust models comes at a significant cost. The training itself becomes much more expensive because of repeated gradient computations and a larger number of training samples. Some real-world models do take up to a month to train [64, 65] on modern hardware and an increase in training cost would be unbearable. Furthermore, if the procedure outlined in [66] does constitute the bare of minimum of steps required to achieve adversarial robustness, then model development cost will rise markedly: threat models have to be designed, transferability must be tested, and a large number of attacks must be run with tuned hyperparameters. For researchers the document recommends to publish the source code and trained models but this is still not happening on a regular basis and won't happen if the genesis of a large model in the article The Machine Learning Reproducibility Crisis is accurate. Even worse, the guideline document does not consider the invariance-based attacks in [14]. (Besides, in my experience determining the state-of-the-art with respect to adversarial examples is in itself challenging currently.)
For some practitioners and researchers the quest for higher model accuracy on standard benchmarks has become their only goal. This sentiment is perfectly expressed by researchers after training the possibly largest and most accurate image recognition models so far in the following statement:
Our work validates the hypothesis that bigger models and more computation would lead to higher model quality.
Apparently, quick training, fast inference, or a small memory footprint are not traits of high-quality models. Likewise, image recognition models were touted as being as "more accurate than humans". On the contrary, popular image recognition models see a notable drop in accuracy with input that is not from the test set [67] and they react much more sensitive than humans to noise [68]. Consequently, a commitment to training adversarially robust models is an acknowledgment that current machine learning models cannot be assumed to match human perception, that there are severe shortcomings in conventional training methods, and that accuracy numbers on popular benchmark datasets are inflated. For corporate machine learning practitioners, a commitment to training adversarially robust models requires an acknowledgement that the model may have a negative impact on the safety of the user but this constitutes a liability for companies. Companies will fight this liability. Case in point: Tesla wrote in a press release that the adversarial attack making a Tesla steer itself into oncoming traffic [31] is "not a real-world concern".
Further Reading
The first adversarial examples were crafted in 2005 to avoid spam filters. [69] summarize the history of adversarial machine learning. [70] is a survey of adversarial attacks in computer vision. Foolbox [71] and cleverhans [72] are software packages providing implementations of algorithms computing adversarial examples. The website https://paperswithcode.com contains an up-to-date list of papers whose code was published.
Appendix: A Note on Matrix Singular Values and Eigenvalues
In the machine learning literature, many authors examine the modulus of the singular values or eigenvalues of the weight matrices in neural networks but the modulus is meaningless if it is not put in relation to the smallest (non-zero) singular values. Weight matrices are used for linear mappings (for matrix vector multiplications) inside a neural network and it holds that 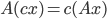 , where
, where  is a scalar,
is a scalar, 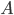 is a matrix, and
is a matrix, and 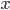 is a vector. If certain eigenvalues of this matrix are deemed too large, one can just scale the matrix; this will affect the output of non-linear activations and the softmax but it will the leave the direction of the vector
is a vector. If certain eigenvalues of this matrix are deemed too large, one can just scale the matrix; this will affect the output of non-linear activations and the softmax but it will the leave the direction of the vector 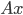 unaltered. Instead, the relevant measure must be either the largest singular value divided by the smallest singular value (the so-called condition number) or the largest singular value divided by the smallest non-zero singular value (the condition number of the full rank part of the matrix). Obviously, an analysis of only the largest singular values ignores the rank of the matrix.
unaltered. Instead, the relevant measure must be either the largest singular value divided by the smallest singular value (the so-called condition number) or the largest singular value divided by the smallest non-zero singular value (the condition number of the full rank part of the matrix). Obviously, an analysis of only the largest singular values ignores the rank of the matrix.
In this context I want to mention Parseval networks [73]. During training, Parseval networks penalize weight matrices that are not approximately orthogonal (a matrix is called orthogonal if 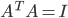 ) and this constrains every entry of the matrix . To see why, consider that the diagonal entries of
) and this constrains every entry of the matrix . To see why, consider that the diagonal entries of 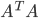 are sums of squares of all entries of and consider that the diagonal entries of must be equal to one, the effect being that the Euclidean norm of the weights is equal to the square root of the matrix dimension. In comparison, weight decay drives the individual matrix entries and consequently all eigenvalues toward zero. Moreover, Parseval networks as regularizers interpret weight matrices really as matrices and not as a collection of real values like weight decay does. Ignoring this property will destroy any structure of the matrix (e.g., symmetry, normality) and lead to severely rank deficient matrices. Parseval networks on the other hand guarantee full rank matrices, i.e., the smallest eigenvalues are non-zero.
are sums of squares of all entries of and consider that the diagonal entries of must be equal to one, the effect being that the Euclidean norm of the weights is equal to the square root of the matrix dimension. In comparison, weight decay drives the individual matrix entries and consequently all eigenvalues toward zero. Moreover, Parseval networks as regularizers interpret weight matrices really as matrices and not as a collection of real values like weight decay does. Ignoring this property will destroy any structure of the matrix (e.g., symmetry, normality) and lead to severely rank deficient matrices. Parseval networks on the other hand guarantee full rank matrices, i.e., the smallest eigenvalues are non-zero.
References
[BibTeX] [Download]
@misc{SzegedyZS2013,
author = {Christian Szegedy and Wojciech Zaremba and Ilya Sutskever and Joan Bruna and Dumitru Erhan and Ian Goodfellow and Rob Fergus},
title = {Intriguing properties of neural networks},
year = {2014},
url = {https://arxiv.org/abs/1312.6199},
archivePrefix = {arXiv},
eprint = {1312.6199},
}[BibTeX] [Download]
@misc{GoodfellowSS2014,
author = {Ian J. Goodfellow and Jonathon Shlens and Christian Szegedy},
title = {Explaining and Harnessing Adversarial Examples},
year = {2014},
url = {https://arxiv.org/abs/1412.6572},
archivePrefix = {arXiv},
eprint = {1412.6572},
}[BibTeX] [Download]
@misc{CisseAN2017,
author = {Moustapha Cisse and Yossi Adi and Natalia Neverova and Joseph Keshet},
title = {Houdini: Fooling Deep Structured Prediction Models},
year = {2017},
url = {https://arxiv.org/abs/1707.05373},
archivePrefix = {arXiv},
eprint = {1707.05373},
}[BibTeX] [Download]
@misc{CroceRH2019,
author = {Francesco Croce and Jonas Rauber and Matthias Hein},
title = {Scaling up the randomized gradient-free adversarial attack reveals overestimation of robustness using established attacks},
year = {2019},
url = {https://arxiv.org/abs/1903.11359},
archivePrefix = {arXiv},
eprint = {1903.11359},
}[BibTeX] [Download]
@article{PapernotMJ2015,
author = {Nicolas Papernot and
Patrick D. McDaniel and
Somesh Jha and
Matt Fredrikson and
Z. Berkay Celik and
Ananthram Swami},
title = {The Limitations of Deep Learning in Adversarial Settings},
journal = {CoRR},
volume = {abs/1511.07528},
year = {2015},
url = {http://arxiv.org/abs/1511.07528},
archivePrefix = {arXiv},
eprint = {1511.07528},
timestamp = {Mon, 13 Aug 2018 16:48:42 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/PapernotMJFCS15},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{RobinsonG2015,
author = {Leigh Robinson and
Benjamin Graham},
title = {Confusing Deep Convolution Networks by Relabelling},
journal = {CoRR},
volume = {abs/1510.06925},
year = {2015},
url = {http://arxiv.org/abs/1510.06925},
archivePrefix = {arXiv},
eprint = {1510.06925},
timestamp = {Mon, 13 Aug 2018 16:47:30 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/RobinsonG15},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{SuVS2017,
author = {Jiawei Su and
Danilo Vasconcellos Vargas and
Kouichi Sakurai},
title = {One pixel attack for fooling deep neural networks},
journal = {CoRR},
volume = {abs/1710.08864},
year = {2017},
url = {http://arxiv.org/abs/1710.08864},
archivePrefix = {arXiv},
eprint = {1710.08864},
timestamp = {Mon, 13 Aug 2018 16:46:37 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1710-08864},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{SongSK2018,
author = {Yang Song and
Rui Shu and
Nate Kushman and
Stefano Ermon},
title = {Generative Adversarial Examples},
journal = {CoRR},
volume = {abs/1805.07894},
year = {2018},
url = {http://arxiv.org/abs/1805.07894},
archivePrefix = {arXiv},
eprint = {1805.07894},
timestamp = {Mon, 13 Aug 2018 16:47:28 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1805-07894},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{HengZJ2018,
author = {Wen Heng and
Shuchang Zhou and
Tingting Jiang},
title = {Harmonic Adversarial Attack Method},
journal = {CoRR},
volume = {abs/1807.10590},
year = {2018},
url = {http://arxiv.org/abs/1807.10590},
archivePrefix = {arXiv},
eprint = {1807.10590},
timestamp = {Mon, 13 Aug 2018 16:47:59 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1807-10590},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{EngstromTS2017,
author = {Logan Engstrom and
Dimitris Tsipras and
Ludwig Schmidt and
Aleksander Madry},
title = {A Rotation and a Translation Suffice: Fooling CNNs with Simple Transformations},
journal = {CoRR},
volume = {abs/1712.02779},
year = {2017},
url = {http://arxiv.org/abs/1712.02779},
archivePrefix = {arXiv},
eprint = {1712.02779},
timestamp = {Mon, 13 Aug 2018 16:48:14 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1712-02779},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{BrownMR2017,
author = {Tom B. Brown and
Dandelion Man{\'{e}} and
Aurko Roy and
Mart{\'{\i}}n Abadi and
Justin Gilmer},
title = {Adversarial Patch},
journal = {CoRR},
volume = {abs/1712.09665},
year = {2017},
url = {http://arxiv.org/abs/1712.09665},
archivePrefix = {arXiv},
eprint = {1712.09665},
timestamp = {Mon, 13 Aug 2018 16:46:21 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1712-09665},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{RosenfeldZT2018,
author = {Amir Rosenfeld and
Richard S. Zemel and
John K. Tsotsos},
title = {The Elephant in the Room},
journal = {CoRR},
volume = {abs/1808.03305},
year = {2018},
url = {http://arxiv.org/abs/1808.03305},
archivePrefix = {arXiv},
eprint = {1808.03305},
timestamp = {Thu, 04 Oct 2018 20:06:33 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1808-03305},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{HosseiniP2018,
author = {Hossein Hosseini and
Radha Poovendran},
title = {Semantic Adversarial Examples},
journal = {CoRR},
volume = {abs/1804.00499},
year = {2018},
url = {http://arxiv.org/abs/1804.00499},
archivePrefix = {arXiv},
eprint = {1804.00499},
timestamp = {Mon, 13 Aug 2018 16:46:08 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1804-00499},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{JacobsenBC2019,
author = {Jacobsen, J{\"{o}}rn{-}Henrik and
Jens Behrmann and
Nicholas Carlini and
Florian Tram{\`{e}}r and
Nicolas Papernot},
title = {Exploiting Excessive Invariance caused by Norm-Bounded Adversarial
Robustness},
journal = {CoRR},
volume = {abs/1903.10484},
year = {2019},
url = {http://arxiv.org/abs/1903.10484},
archivePrefix = {arXiv},
eprint = {1903.10484},
timestamp = {Mon, 01 Apr 2019 14:07:37 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1903-10484},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{Moosavi-DezfooliFF2015,
author = {Moosavi-Dezfooli, Seyed-Mohsen and
Alhussein Fawzi and
Pascal Frossard},
title = {DeepFool: a simple and accurate method to fool deep neural networks},
journal = {CoRR},
volume = {abs/1511.04599},
year = {2015},
url = {http://arxiv.org/abs/1511.04599},
archivePrefix = {arXiv},
eprint = {1511.04599},
timestamp = {Mon, 13 Aug 2018 16:47:14 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/Moosavi-Dezfooli15},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{Moosavi-DezfooliFF2016,
author = {Moosavi-Dezfooli, Seyed-Mohsen and
Alhussein Fawzi and
Omar Fawzi and
Pascal Frossard},
title = {Universal adversarial perturbations},
journal = {CoRR},
volume = {abs/1610.08401},
year = {2016},
url = {http://arxiv.org/abs/1610.08401},
archivePrefix = {arXiv},
eprint = {1610.08401},
timestamp = {Mon, 13 Aug 2018 16:48:58 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/Moosavi-Dezfooli16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{YooPC2017,
author = {Young Joon Yoo and
Seonguk Park and
Junyoung Choi and
Sangdoo Yun and
Nojun Kwak},
title = {Butterfly Effect: Bidirectional Control of Classification Performance
by Small Additive Perturbation},
journal = {CoRR},
volume = {abs/1711.09681},
year = {2017},
url = {http://arxiv.org/abs/1711.09681},
archivePrefix = {arXiv},
eprint = {1711.09681},
timestamp = {Mon, 13 Aug 2018 16:47:19 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1711-09681},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{ElsayedGS2018,
author = {Gamaleldin F. Elsayed and
Ian J. Goodfellow and
Sohl{-}Dickstein, Jasha},
title = {Adversarial Reprogramming of Neural Networks},
journal = {CoRR},
volume = {abs/1806.11146},
year = {2018},
url = {http://arxiv.org/abs/1806.11146},
archivePrefix = {arXiv},
eprint = {1806.11146},
timestamp = {Mon, 13 Aug 2018 16:46:25 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1806-11146},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{TramerPG2017,
author = {Florian Tram\`{e}r and Nicolas Papernot and Ian Goodfellow and Dan Boneh and Patrick McDaniel},
title = {The Space of Transferable Adversarial Examples},
year = {2017},
url = {https://arxiv.org/abs/1704.03453},
archivePrefix = {arXiv},
eprint = {1704.03453},
}[BibTeX] [Download]
@article{PapernotMG2016a,
author = {Nicolas Papernot and
Patrick D. McDaniel and
Ian J. Goodfellow and
Somesh Jha and
Z. Berkay Celik and
Ananthram Swami},
title = {Practical Black-Box Attacks against Deep Learning Systems using Adversarial
Examples},
journal = {CoRR},
volume = {abs/1602.02697},
year = {2016},
url = {http://arxiv.org/abs/1602.02697},
archivePrefix = {arXiv},
eprint = {1602.02697},
timestamp = {Mon, 13 Aug 2018 16:49:06 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/PapernotMGJCS16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{PapernotMG2016b,
author = {Nicolas Papernot and
Patrick D. McDaniel and
Ian J. Goodfellow},
title = {Transferability in Machine Learning: from Phenomena to Black-Box Attacks
using Adversarial Samples},
journal = {CoRR},
volume = {abs/1605.07277},
year = {2016},
url = {http://arxiv.org/abs/1605.07277},
archivePrefix = {arXiv},
eprint = {1605.07277},
timestamp = {Mon, 13 Aug 2018 16:48:28 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/PapernotMG16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{NarodytskaK2016,
author = {Nina Narodytska and
Shiva Prasad Kasiviswanathan},
title = {Simple Black-Box Adversarial Perturbations for Deep Networks},
journal = {CoRR},
volume = {abs/1612.06299},
year = {2016},
url = {http://arxiv.org/abs/1612.06299},
archivePrefix = {arXiv},
eprint = {1612.06299},
timestamp = {Mon, 13 Aug 2018 16:46:18 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/NarodytskaK16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{ChenSZ2017,
author = {Pin-Yu Chen and Yash Sharma and Huan Zhang and Jinfeng Yi and
Cho-Jui Hsieh},
title = {EAD: Elastic-Net Attacks to Deep Neural Networks via Adversarial Examples},
year = {2017},
url = {https://arxiv.org/abs/1709.04114},
archivePrefix = {arXiv},
eprint = {1709.04114},
}[BibTeX] [Download]
@inproceedings{BrendelRB2018,
author = {Wieland Brendel and
Jonas Rauber and
Matthias Bethge},
title = {Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box
Machine Learning Models},
booktitle = {6th International Conference on Learning Representations, {ICLR} 2018,
Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings},
year = {2018},
crossref = {DBLP:conf/iclr/2018},
url = {https://openreview.net/forum?id=SyZI0GWCZ},
timestamp = {Thu, 04 Apr 2019 13:20:09 +0200},
biburl = {https://dblp.org/rec/bib/conf/iclr/BrendelRB18},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{NguyenYC2014,
author = {Anh Mai Nguyen and
Jason Yosinski and
Jeff Clune},
title = {Deep Neural Networks are Easily Fooled: High Confidence Predictions
for Unrecognizable Images},
journal = {CoRR},
volume = {abs/1412.1897},
year = {2014},
url = {http://arxiv.org/abs/1412.1897},
archivePrefix = {arXiv},
eprint = {1412.1897},
timestamp = {Mon, 13 Aug 2018 16:48:10 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/NguyenYC14},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{KurakinGB2016a,
author = {Alexey Kurakin and
Ian J. Goodfellow and
Samy Bengio},
title = {Adversarial examples in the physical world},
journal = {CoRR},
volume = {abs/1607.02533},
year = {2016},
url = {http://arxiv.org/abs/1607.02533},
archivePrefix = {arXiv},
eprint = {1607.02533},
timestamp = {Mon, 13 Aug 2018 16:48:46 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/KurakinGB16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{AthalyeEI2017,
author = {Anish Athalye and
Logan Engstrom and
Andrew Ilyas and
Kevin Kwok},
title = {Synthesizing Robust Adversarial Examples},
journal = {CoRR},
volume = {abs/1707.07397},
year = {2017},
url = {http://arxiv.org/abs/1707.07397},
archivePrefix = {arXiv},
eprint = {1707.07397},
timestamp = {Mon, 13 Aug 2018 16:48:27 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/AthalyeS17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{EvtimovEF2017,
author = {Ivan Evtimov and
Kevin Eykholt and
Earlence Fernandes and
Tadayoshi Kohno and
Bo Li and
Atul Prakash and
Amir Rahmati and
Dawn Song},
title = {Robust Physical-World Attacks on Machine Learning Models},
journal = {CoRR},
volume = {abs/1707.08945},
year = {2017},
url = {http://arxiv.org/abs/1707.08945},
archivePrefix = {arXiv},
eprint = {1707.08945},
timestamp = {Mon, 20 Aug 2018 13:55:57 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/EvtimovEFKLPRS17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{LiSK2019,
author = {Juncheng Li and Frank R. Schmidt and J. Zico Kolter},
title = {Adversarial camera stickers: A physical camera-based attack on deep learning systems},
year = {2019},
url = {https://arxiv.org/abs/1904.00759},
archivePrefix = {arXiv},
eprint = {1904.00759},
}[BibTeX] [Download]
@article{YangXL2018,
author = {Dawei Yang and
Chaowei Xiao and
Bo Li and
Jia Deng and
Mingyan Liu},
title = {Realistic Adversarial Examples in 3D Meshes},
journal = {CoRR},
volume = {abs/1810.05206},
year = {2018},
url = {http://arxiv.org/abs/1810.05206},
archivePrefix = {arXiv},
eprint = {1810.05206},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1810-05206},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{Keen2019,
author = {{Tencent Keen Security Lab}},
title = {Experimental Security Research of Tesla Autopilot},
year = {2019},
url = {https://keenlab.tencent.com/en/2019/03/29/Tencent-Keen-Security-Lab-Experimental-Security-Research-of-Tesla-Autopilot/},
}[BibTeX] [Download]
@article{AlzantotSE2018,
author = {Moustafa Alzantot and
Yash Sharma and
Ahmed Elgohary and
Ho, Bo{-}Jhang and
Mani B. Srivastava and
Chang, Kai{-}Wei},
title = {Generating Natural Language Adversarial Examples},
journal = {CoRR},
volume = {abs/1804.07998},
year = {2018},
url = {http://arxiv.org/abs/1804.07998},
archivePrefix = {arXiv},
eprint = {1804.07998},
timestamp = {Mon, 13 Aug 2018 16:46:19 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1804-07998},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{GrossePM2016,
author = {Kathrin Grosse and
Nicolas Papernot and
Praveen Manoharan and
Michael Backes and
Patrick D. McDaniel},
title = {Adversarial Perturbations Against Deep Neural Networks for Malware
Classification},
journal = {CoRR},
volume = {abs/1606.04435},
year = {2016},
url = {http://arxiv.org/abs/1606.04435},
archivePrefix = {arXiv},
eprint = {1606.04435},
timestamp = {Mon, 13 Aug 2018 16:47:14 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/GrossePM0M16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@inproceedings{CarliniMV2016,
author = {Nicholas Carlini and
Pratyush Mishra and
Tavish Vaidya and
Yuankai Zhang and
Micah Sherr and
Clay Shields and
David A. Wagner and
Wenchao Zhou},
title = {Hidden Voice Commands},
booktitle = {25th {USENIX} Security Symposium, {USENIX} Security 16, Austin, TX,
USA, August 10-12, 2016.},
pages = {513--530},
year = {2016},
crossref = {DBLP:conf/uss/2016},
url = {https://www.usenix.org/conference/usenixsecurity16/technical-sessions/presentation/carlini},
timestamp = {Wed, 14 Jun 2017 15:21:24 +0200},
biburl = {https://dblp.org/rec/bib/conf/uss/CarliniMVZSSWZ16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@techreport{IterHJ2016,
author = {Dan Iter and
Jade Huang and
Mike Jerman},
title = {Generating Adversarial Examples for Speech Recognition},
year = {2016},
url = {http://web.stanford.edu/class/cs224s/reports/Dan_Iter.pdf},
institution = {Stanford University},
}[BibTeX] [Download]
@misc{QinCG2019,
author = {Yao Qin and Nicholas Carlini and Ian Goodfellow and Garrison Cottrell and Colin Raffel},
title = {Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition},
year = {2019},
url = {https://arxiv.org/abs/1903.10346},
archivePrefix = {arXiv},
eprint = {1903.10346},
}[BibTeX] [Download]
@article{FinlaysonKB2018,
author = {Samuel G. Finlayson and
Isaac S. Kohane and
Andrew L. Beam},
title = {Adversarial Attacks Against Medical Deep Learning Systems},
journal = {CoRR},
volume = {abs/1804.05296},
year = {2018},
url = {http://arxiv.org/abs/1804.05296},
archivePrefix = {arXiv},
eprint = {1804.05296},
timestamp = {Mon, 13 Aug 2018 16:48:58 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1804-05296},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{BrendelB2017,
author = {Wieland Brendel and Matthias Bethge},
title = {Comment on "Biologically inspired protection of deep networks from adversarial attacks"},
year = {2017},
url = {https://arxiv.org/abs/1704.01547},
archivePrefix = {arXiv},
eprint = {1704.01547},
}[BibTeX] [Download]
@article{Carlini2019,
author = {Nicholas Carlini},
title = {Is AmI (Attacks Meet Interpretability) Robust to Adversarial Examples?},
journal = {CoRR},
volume = {abs/1902.02322},
year = {2019},
url = {http://arxiv.org/abs/1902.02322},
archivePrefix = {arXiv},
eprint = {1902.02322},
timestamp = {Fri, 01 Mar 2019 17:14:17 +0100},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1902-02322},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{CarliniW2016a,
author = {Nicholas Carlini and
David A. Wagner},
title = {Defensive Distillation is Not Robust to Adversarial Examples},
journal = {CoRR},
volume = {abs/1607.04311},
year = {2016},
url = {http://arxiv.org/abs/1607.04311},
archivePrefix = {arXiv},
eprint = {1607.04311},
timestamp = {Mon, 13 Aug 2018 16:49:17 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/CarliniW16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{MetzenGF2017,
author = {Jan Hendrik Metzen and Tim Genewein and Volker Fischer and Bastian Bischoff},
title = {On Detecting Adversarial Perturbations},
year = {2017},
url = {https://arxiv.org/abs/1702.04267},
archivePrefix = {arXiv},
eprint = {1702.04267},
}[BibTeX] [Download]
@article{CarliniW2017,
author = {Nicholas Carlini and
David A. Wagner},
title = {Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection
Methods},
journal = {CoRR},
volume = {abs/1705.07263},
year = {2017},
url = {http://arxiv.org/abs/1705.07263},
archivePrefix = {arXiv},
eprint = {1705.07263},
timestamp = {Mon, 13 Aug 2018 16:46:30 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/CarliniW17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{AthalyeCW2018,
author = {Anish Athalye and
Nicholas Carlini and
David A. Wagner},
title = {Obfuscated Gradients Give a False Sense of Security: Circumventing
Defenses to Adversarial Examples},
journal = {CoRR},
volume = {abs/1802.00420},
year = {2018},
url = {http://arxiv.org/abs/1802.00420},
archivePrefix = {arXiv},
eprint = {1802.00420},
timestamp = {Mon, 13 Aug 2018 16:48:14 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1802-00420},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{Dube2018,
author = {Simant Dube},
title = {High Dimensional Spaces, Deep Learning and Adversarial Examples},
journal = {CoRR},
volume = {abs/1801.00634},
year = {2018},
url = {http://arxiv.org/abs/1801.00634},
archivePrefix = {arXiv},
eprint = {1801.00634},
timestamp = {Mon, 13 Aug 2018 16:48:10 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1801-00634},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{GilmerMF2018,
author = {Justin Gilmer and
Luke Metz and
Fartash Faghri and
Samuel S. Schoenholz and
Maithra Raghu and
Martin Wattenberg and
Ian J. Goodfellow},
title = {Adversarial Spheres},
journal = {CoRR},
volume = {abs/1801.02774},
year = {2018},
url = {http://arxiv.org/abs/1801.02774},
archivePrefix = {arXiv},
eprint = {1801.02774},
timestamp = {Mon, 13 Aug 2018 16:46:17 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1801-02774},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{ShafahiHS2018,
author = {Ali Shafahi and
W. Ronny Huang and
Christoph Studer and
Soheil Feizi and
Tom Goldstein},
title = {Are adversarial examples inevitable?},
journal = {CoRR},
volume = {abs/1809.02104},
year = {2018},
url = {http://arxiv.org/abs/1809.02104},
archivePrefix = {arXiv},
eprint = {1809.02104},
timestamp = {Fri, 05 Oct 2018 11:34:52 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1809-02104},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@inproceedings{AggarwalHK2001,
author = {Charu C. Aggarwal and
Alexander Hinneburg and
Daniel A. Keim},
title = {On the Surprising Behavior of Distance Metrics in High Dimensional
Spaces},
booktitle = {Database Theory - {ICDT} 2001, 8th International Conference, London,
UK, January 4-6, 2001, Proceedings.},
pages = {420--434},
year = {2001},
crossref = {DBLP:conf/icdt/2001},
url = {http://users.informatik.uni-halle.de/~hinnebur/PS_Files/icdt2001b.pdf},
doi = {10.1007/3-540-44503-X\_27},
timestamp = {Wed, 24 May 2017 15:40:45 +0200},
biburl = {https://dblp.org/rec/bib/conf/icdt/AggarwalHK01},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@inproceedings{BeyerGR1999,
author = {Kevin S. Beyer and
Jonathan Goldstein and
Raghu Ramakrishnan and
Uri Shaft},
title = {When Is ``Nearest Neighbor'' Meaningful?},
booktitle = {Database Theory - {ICDT} '99, 7th International Conference, Jerusalem,
Israel, January 10-12, 1999, Proceedings.},
pages = {217--235},
year = {1999},
crossref = {DBLP:conf/icdt/99},
url = {https://members.loria.fr/moberger/Enseignement/Master2/Exposes/beyer.pdf},
doi = {10.1007/3-540-49257-7\_15},
timestamp = {Wed, 14 Nov 2018 10:56:23 +0100},
biburl = {https://dblp.org/rec/bib/conf/icdt/BeyerGRS99},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@techreport{Rojas2015,
author = {Ra\'{u}l Rojas},
title = {The Curse of Dimensionality},
year = {2015},
url = {https://www.inf.fu-berlin.de/inst/ag-ki/rojas_home/documents/tutorials/dimensionality.pdf},
institution = {Freie Universit\"{a}t Berlin},
}[BibTeX] [Download]
@article{FordGC2019,
author = {Nic Ford and
Justin Gilmer and
Nicolas Carlini and
Dogus Cubuk},
title = {Adversarial Examples Are a Natural Consequence of Test Error in Noise},
journal = {CoRR},
volume = {abs/1901.10513},
year = {2019},
url = {http://arxiv.org/abs/1901.10513},
archivePrefix = {arXiv},
eprint = {1901.10513},
timestamp = {Sun, 03 Feb 2019 14:23:05 +0100},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1901-10513},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{FawziMF2016,
author = {Alhussein Fawzi and
Moosavi-Dezfooli, Seyed-Mohsen and
Pascal Frossard},
title = {Robustness of classifiers: from adversarial to random noise},
journal = {CoRR},
volume = {abs/1608.08967},
year = {2016},
url = {http://arxiv.org/abs/1608.08967},
archivePrefix = {arXiv},
eprint = {1608.08967},
timestamp = {Mon, 13 Aug 2018 16:47:18 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/FawziMF16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{FawziMF2017,
author = {Alhussein Fawzi and
Moosavi-Dezfooli, Seyed-Mohsen and
Pascal Frossard and
Stefano Soatto},
title = {Classification regions of deep neural networks},
journal = {CoRR},
volume = {abs/1705.09552},
year = {2017},
url = {http://arxiv.org/abs/1705.09552},
archivePrefix = {arXiv},
eprint = {1705.09552},
timestamp = {Mon, 13 Aug 2018 16:49:15 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/FawziMFS17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{Moosavi-DezfooliFF2017,
author = {Moosavi-Dezfooli, Seyed-Mohsen and
Alhussein Fawzi and
Omar Fawzi and
Pascal Frossard and
Stefano Soatto},
title = {Analysis of universal adversarial perturbations},
journal = {CoRR},
volume = {abs/1705.09554},
year = {2017},
url = {http://arxiv.org/abs/1705.09554},
archivePrefix = {arXiv},
eprint = {1705.09554},
timestamp = {Mon, 13 Aug 2018 16:48:18 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/Moosavi-Dezfooli17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{SchmidtST2018,
author = {Ludwig Schmidt and
Shibani Santurkar and
Dimitris Tsipras and
Kunal Talwar and
Aleksander Madry},
title = {Adversarially Robust Generalization Requires More Data},
journal = {CoRR},
volume = {abs/1804.11285},
year = {2018},
url = {http://arxiv.org/abs/1804.11285},
archivePrefix = {arXiv},
eprint = {1804.11285},
timestamp = {Mon, 13 Aug 2018 16:46:50 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1804-11285},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{TsiprasSE2018,
author = {Dimitris Tsipras and Shibani Santurkar and Logan Engstrom and Alexander Turner and Aleksander Madry},
title = {Robustness May Be at Odds with Accuracy},
year = {2018},
url = {https://arxiv.org/abs/1805.12152},
archivePrefix = {arXiv},
eprint = {1805.12152},
}[BibTeX] [Download]
@misc{MadryMS2017,
author = {Aleksander Madry and Aleksandar Makelov and Ludwig Schmidt and Dimitris Tsipras and Adrian Vladu},
title = {Towards Deep Learning Models Resistant to Adversarial Attacks},
year = {2017},
url = {https://arxiv.org/abs/1706.06083},
archivePrefix = {arXiv},
eprint = {1706.06083},
}[BibTeX] [Download]
@article{CarliniKB2017,
author = {Nicholas Carlini and
Guy Katz and
Clark Barrett and
David L. Dill},
title = {Provably Minimally-Distorted Adversarial Examples},
journal = {CoRR},
volume = {abs/1709.10207},
year = {2017},
url = {http://arxiv.org/abs/1709.10207},
archivePrefix = {arXiv},
eprint = {1709.10207},
timestamp = {Mon, 13 Aug 2018 16:45:59 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1709-10207},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{RosenfeldT2018,
author = {Amir Rosenfeld and
John K. Tsotsos},
title = {Intriguing Properties of Randomly Weighted Networks: Generalizing
While Learning Next to Nothing},
journal = {CoRR},
volume = {abs/1802.00844},
year = {2018},
url = {http://arxiv.org/abs/1802.00844},
archivePrefix = {arXiv},
eprint = {1802.00844},
timestamp = {Mon, 13 Aug 2018 16:48:06 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1802-00844},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{GallowayTM2018,
author = {Angus Galloway and
Graham W. Taylor and
Medhat Moussa},
title = {Predicting Adversarial Examples with High Confidence},
journal = {CoRR},
volume = {abs/1802.04457},
year = {2018},
url = {http://arxiv.org/abs/1802.04457},
archivePrefix = {arXiv},
eprint = {1802.04457},
timestamp = {Mon, 13 Aug 2018 16:48:30 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1802-04457},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{GallowayTT2018,
author = {Angus Galloway and
Thomas Tanay and
Graham W. Taylor},
title = {Adversarial Training Versus Weight Decay},
journal = {CoRR},
volume = {abs/1804.03308},
year = {2018},
url = {http://arxiv.org/abs/1804.03308},
archivePrefix = {arXiv},
eprint = {1804.03308},
timestamp = {Mon, 13 Aug 2018 16:46:27 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1804-03308},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{ZhangL2015,
author = {Xiang Zhang and
Yann LeCun},
title = {Universum Prescription: Regularization using Unlabeled Data},
journal = {CoRR},
volume = {abs/1511.03719},
year = {2015},
url = {http://arxiv.org/abs/1511.03719},
archivePrefix = {arXiv},
eprint = {1511.03719},
timestamp = {Mon, 13 Aug 2018 16:46:50 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/ZhangL15e},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{RothKH2019,
author = {Kevin Roth and
Yannic Kilcher and
Thomas Hofmann},
title = {The Odds are Odd: {A} Statistical Test for Detecting Adversarial Examples},
journal = {CoRR},
volume = {abs/1902.04818},
year = {2019},
url = {http://arxiv.org/abs/1902.04818},
archivePrefix = {arXiv},
eprint = {1902.04818},
timestamp = {Sat, 02 Mar 2019 16:35:40 +0100},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1902-04818},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{TabacofV2015,
author = {Pedro Tabacof and
Eduardo Valle},
title = {Exploring the Space of Adversarial Images},
journal = {CoRR},
volume = {abs/1510.05328},
year = {2015},
url = {http://arxiv.org/abs/1510.05328},
archivePrefix = {arXiv},
eprint = {1510.05328},
timestamp = {Mon, 13 Aug 2018 16:47:48 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/TabacofV15},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@inproceedings{VarianiBM2017,
author = {Ehsan Variani and
Tom Bagby and
Erik McDermott and
Michiel Bacchiani},
title = {End-to-End Training of Acoustic Models for Large Vocabulary Continuous
Speech Recognition with TensorFlow},
booktitle = {Interspeech 2017, 18th Annual Conference of the International Speech
Communication Association, Stockholm, Sweden, August 20-24, 2017},
pages = {1641--1645},
year = {2017},
crossref = {DBLP:conf/interspeech/2017},
url = {https://research.google.com/pubs/archive/46294.pdf},
timestamp = {Tue, 16 Jan 2018 11:21:54 +0100},
biburl = {https://dblp.org/rec/bib/conf/interspeech/VarianiBMB17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{ZhangCF2019,
author = {Wei Zhang and Xiaodong Cui and Ulrich Finkler and Brian Kingsbury and George Saon and David Kung and Michael Picheny},
title = {Distributed Deep Learning Strategies For Automatic Speech Recognition},
year = {2019},
url = {https://arxiv.org/abs/1904.04956},
archivePrefix = {arXiv},
eprint = {1904.04956},
}[BibTeX] [Download]
@article{CarliniAP2019,
author = {Nicholas Carlini and
Anish Athalye and
Nicolas Papernot and
Wieland Brendel and
Jonas Rauber and
Dimitris Tsipras and
Ian J. Goodfellow and
Aleksander Madry and
Alexey Kurakin},
title = {On Evaluating Adversarial Robustness},
journal = {CoRR},
volume = {abs/1902.06705},
year = {2019},
url = {http://arxiv.org/abs/1902.06705},
archivePrefix = {arXiv},
eprint = {1902.06705},
timestamp = {Sat, 02 Mar 2019 16:35:38 +0100},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1902-06705},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{RechtRS2019,
author = {Benjamin Recht and
Rebecca Roelofs and
Ludwig Schmidt and
Vaishaal Shankar},
title = {Do ImageNet Classifiers Generalize to ImageNet?},
journal = {CoRR},
volume = {abs/1902.10811},
year = {2019},
url = {http://arxiv.org/abs/1902.10811},
archivePrefix = {arXiv},
eprint = {1902.10811},
timestamp = {Mon, 04 Mar 2019 15:54:38 +0100},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1902-10811},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{GeirhosMR2018,
author = {Robert Geirhos and
Carlos R. Medina Temme and
Jonas Rauber and
Heiko H. Sch{\"{u}}tt and
Matthias Bethge and
Felix A. Wichmann},
title = {Generalisation in humans and deep neural networks},
journal = {CoRR},
volume = {abs/1808.08750},
year = {2018},
url = {http://arxiv.org/abs/1808.08750},
archivePrefix = {arXiv},
eprint = {1808.08750},
timestamp = {Sun, 02 Sep 2018 15:01:55 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1808-08750},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{BiggioR2017,
author = {Battista Biggio and
Fabio Roli},
title = {Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning},
journal = {CoRR},
volume = {abs/1712.03141},
year = {2017},
url = {http://arxiv.org/abs/1712.03141},
archivePrefix = {arXiv},
eprint = {1712.03141},
timestamp = {Mon, 13 Aug 2018 16:48:36 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1712-03141},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{AkhtarM2018,
author = {Naveed Akhtar and
Ajmal Mian},
title = {Threat of Adversarial Attacks on Deep Learning in Computer Vision:
{A} Survey},
journal = {CoRR},
volume = {abs/1801.00553},
year = {2018},
url = {http://arxiv.org/abs/1801.00553},
archivePrefix = {arXiv},
eprint = {1801.00553},
timestamp = {Mon, 13 Aug 2018 16:48:49 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1801-00553},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{RauberBB2017,
author = {Jonas Rauber and
Wieland Brendel and
Matthias Bethge},
title = {Foolbox v0.8.0: {A} Python toolbox to benchmark the robustness of
machine learning models},
journal = {CoRR},
volume = {abs/1707.04131},
year = {2017},
url = {http://arxiv.org/abs/1707.04131},
archivePrefix = {arXiv},
eprint = {1707.04131},
timestamp = {Mon, 13 Aug 2018 16:46:53 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/RauberBB17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@article{GoodfellowPM2016,
author = {Ian J. Goodfellow and
Nicolas Papernot and
Patrick D. McDaniel},
title = {cleverhans v0.1: an adversarial machine learning library},
journal = {CoRR},
volume = {abs/1610.00768},
year = {2016},
url = {http://arxiv.org/abs/1610.00768},
archivePrefix = {arXiv},
eprint = {1610.00768},
timestamp = {Mon, 13 Aug 2018 16:47:06 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/GoodfellowPM16},
bibsource = {dblp computer science bibliography, https://dblp.org}
}[BibTeX] [Download]
@misc{CisseBG2017,
author = {Moustapha Cisse and Piotr Bojanowski and Edouard Grave and Yann Dauphin and Nicolas Usunier},
title = {Parseval Networks: Improving Robustness to Adversarial Examples},
year = {2017},
url = {https://arxiv.org/abs/1704.08847},
archivePrefix = {arXiv},
eprint = {1704.08847},
}