For my master's thesis I implemented multiple solvers for structured generalized eigenvalue problems using LAPACK. In this post, I will briefly discuss a method to simplify the memory management and ways to catch programming errors as early as possible when implementing a solver for linear algebra problems that uses LAPACK. The advice in this post only supplements good programming practices like using version control systems and automated tests.
Plan the Memory Layout before Programming
LAPACK is stateless, it does not allocate memory on its own, it can operate on submatrices, and it overwrites existing matrices if it can. Moreover, LAPACK's memory demand may depend on the matrices at hand. Thus, memory managent is challenging when LAPACK is involved. I found it helpful to plan the memory layout with a table. As an example, the table below contains the memory layout for a solver for generalized eigenvalue problems 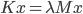 with real symmetric positive semidefinite matrices using QR factorizations and the CS decomposition. Double hyphens signify unitialized or unknown memory contents (unknown memory contents are caused by LAPACK functions using matrices given to them as additional workspace). The rows show the content of the different memory locations after the operation in the first column executed.
with real symmetric positive semidefinite matrices using QR factorizations and the CS decomposition. Double hyphens signify unitialized or unknown memory contents (unknown memory contents are caused by LAPACK functions using matrices given to them as additional workspace). The rows show the content of the different memory locations after the operation in the first column executed.
The first step is to scale the mass matrix such that 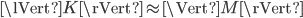 . To that end, the solver calculates a factor
. To that end, the solver calculates a factor 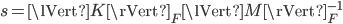 , where
, where 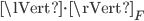 is the Frobenius norm, and multiplies the mass matrix with it. Next, it computes the Cholesky factorizations with pivoting giving matrices
is the Frobenius norm, and multiplies the mass matrix with it. Next, it computes the Cholesky factorizations with pivoting giving matrices 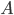 and
and 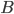 with
with 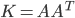 ,
, 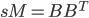 . The solver tests if the matrices are numerically positive semidefinite by examining the residual of
. The solver tests if the matrices are numerically positive semidefinite by examining the residual of 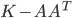 and
and 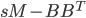 . Hence the calls to dlacpy (copies a matrix) and dgemm (matrix-matrix multiplication). The next step is the calculation of the generalized singular value decomposition (GSVD) of
. Hence the calls to dlacpy (copies a matrix) and dgemm (matrix-matrix multiplication). The next step is the calculation of the generalized singular value decomposition (GSVD) of 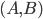 before finally computing the transposed matrix of eigenvectors
before finally computing the transposed matrix of eigenvectors 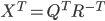 and the eigenvalues
and the eigenvalues
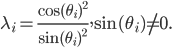
| Operation/memory size | n2 | n2 | n | n2 | Workspace size |
|---|---|---|---|---|---|
| Initial State | |||||
| K | M | -- | -- | ||
| Scale mass matrix | |||||
| dlansy | K | M | -- | -- | |
| dlascl | K | sM | -- | -- | |
| Cholesky factorization sM | |||||
| dlacpy | K | sM | -- | sM | |
| dpstrf | K | B | -- | sM | 2n |
| dgemm | K | B | -- | 0 | |
| Cholesky factorization K | |||||
| dlacpy | K | B | -- | K | |
| dpstrf | K | B | -- | A | 2n |
| dgemm | 0 | B | -- | A | |
| Compute GSVD of (A,B) | |||||
| dggsvdcs | QT | R | Ɵ | -- | 2n2 |
| Compute eigenvectors X | |||||
| dtrsm | XT | R | Ɵ | -- | |
| Compute eigenvalues | |||||
| XT | R | Λ | -- |
Complement Tests using Diagonal Matrices
Identity matrices are the least likely to reveal bugs because they are permutation invariant; diagonal matrices are less likely to reveal bugs involving matrix transposes. Bidiagonal or tridiagonal matrices avoid these problems and should provide a good compromise between complexity and effectiveness. I had to debug a solver because a test problem of dimension 3600 had inaccurate solutions due to a wrongly applied matrix transpose; all my tests were using diagonal matrices.
Try Direct Search Optimization for Finding Bugs
Given a function 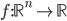 and a starting vector
and a starting vector 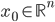 , a direct search optimizer is a method finds extremal values of
, a direct search optimizer is a method finds extremal values of 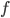 by repeatedly evaluating
by repeatedly evaluating 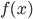 ,
,  . Consequently, these methods can also find extremal values of non-continuous functions. Examples for direct search methods are the alternating directions method, the multidirectional search method, and the Nelder-Mead method. All the solvers implemented for my master's thesis were numerically stable so inaccurate results would indicate a software bug. Hence I used direct search optimization to maximize the error of the computed solutions for small problems (eight degrees of freedom or less). Specifically, the solver computes all eigenpairs of a generalized eigenvalue problem and the optimizer had to maximize the largest backward error. The setup is easy because there was already a function for assessing solution error and because the Nelder-Mead method is available in SciPy so all that was needed for this procedure were methods to turn vectors in matrix pairs (direct search optimizers work only with vectors) and a loop feeding different starting values to the optimization method. The optimizer found bugs but I did not document which ones (I found it irrelevant when writing the thesis).
. Consequently, these methods can also find extremal values of non-continuous functions. Examples for direct search methods are the alternating directions method, the multidirectional search method, and the Nelder-Mead method. All the solvers implemented for my master's thesis were numerically stable so inaccurate results would indicate a software bug. Hence I used direct search optimization to maximize the error of the computed solutions for small problems (eight degrees of freedom or less). Specifically, the solver computes all eigenpairs of a generalized eigenvalue problem and the optimizer had to maximize the largest backward error. The setup is easy because there was already a function for assessing solution error and because the Nelder-Mead method is available in SciPy so all that was needed for this procedure were methods to turn vectors in matrix pairs (direct search optimizers work only with vectors) and a loop feeding different starting values to the optimization method. The optimizer found bugs but I did not document which ones (I found it irrelevant when writing the thesis).
Initialize Memory to NaN
NaNs propagate in every computation so you are guaranteed to notice the improper use of memory. This hint is most helpful for finding code using the wrong submatrix, e.g., using the upper-triangular part of a matrix instead of the lower-triangular part.
Use Assertions
Use assertions throughout your code because assertions belong to the set of tools with empirical evidence of their efficacy. Even in a solver for problems involving matrices, there are plenty of opportunities for easily computable and effective assertions. Moreover, use assertions even for code not written by you. This is useful for detecting bugs and unexpected return values, e.g., if you misunderstood the documentation. Assertions quickly detected a problem where I was mistaken about the order of the generalized singular values returned by xGGSVD3. Furthermore, LAPACK bug 139 was found by an assertion and the problem with workspace queries in single precision (see below) was also detected by an assertion.
Do Workspace Queries in Double Precision
LAPACK returns the optimal workspace size as a floating point variable and a single-precision float variable has 24 significand bits (normalized representation) so workspace sizes larger than 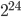 are subject to round-off. This is a small value, e.g., given an
are subject to round-off. This is a small value, e.g., given an 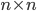 matrix, the minimum workspace size for the divide-and-conquer solver for real symmetric eigenvalue problems xSYEVD is
matrix, the minimum workspace size for the divide-and-conquer solver for real symmetric eigenvalue problems xSYEVD is 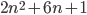 meaning the workspace size will be subject to round-off for
meaning the workspace size will be subject to round-off for 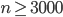 . The largest dense test problem in my master's thesis has dimension 3600 and these can be solved within minutes on an off-the-shelf computer nowadays. Consequently, you should do workspace queries in double precision; the 53 significand bits offer enough precision for current computers and in fact, certain 64 bit CPUs use only 48 bits for memory addressing at the moment.
. The largest dense test problem in my master's thesis has dimension 3600 and these can be solved within minutes on an off-the-shelf computer nowadays. Consequently, you should do workspace queries in double precision; the 53 significand bits offer enough precision for current computers and in fact, certain 64 bit CPUs use only 48 bits for memory addressing at the moment.
Note that LAPACK internally uses integers when computing the workspace sizes.